今天的内容是线性回归的正则化扩展。正则化能有效的解决过拟合(overfitting)的问题。
本质上讲,过拟合就是模型过于复杂,复杂到削弱了它的泛化性能。由于训练数据的数目是有限的,因此我们总是可以通过增加参数的数量来提升模型的复杂度,进而降低训练误差。然而,学习的本领越专精,应用的口径就越狭窄,过于复杂的模型能在训练集上获得很好的拟合效果,但是在测试集上拟合效果很差,即模型的范化性能差。
正则化(regularization)是用于抑制过拟合的方法的统称,它通过动态调整估计参数的取值来降低模型的复杂度,以偏差的增加为代价来换取方差的下降。这是因为当一些参数足够小时,它们对应的属性对输出结果的贡献就会微乎其微,这在实质上去除了非相关属性的影响。
在线性回归里,最常见的正则化方式就是在损失函数(loss function)中添加正则化项(regularizer),而添加的正则化项 $R(\lambda)$ 往往是待估计参数的 $p$- 范数。将均方误差和参数的范数之和作为一个整体来进行约束优化,相当于额外添加了一重关于参数的限制条件,避免大量参数同时出现较大的取值。由于正则化的作用通常是让参数估计值的幅度下降,因此在统计学中它也被称为系数收缩方法(shrinkage method)。
将正则化项应用在基于最小二乘法的线性回归中,就可以得到线性回归的不同修正(penalized linear regression)。当正则化项为 2- 范数的平方时,修正结果就是岭回归;当正则化项为 1- 范数时,修正结果就是LASSO。岭回归和 LASSO 具有不同的几何意义。下图给出的是岭回归(左)和 LASSO(右)的可视化表示。图中的蓝色点表示普通最小二乘法计算出的最优参数,外面的每个蓝色圆圈都是损失函数的等值线,每个圆圈上的误差都是相等的,从里到外误差则越来越大。
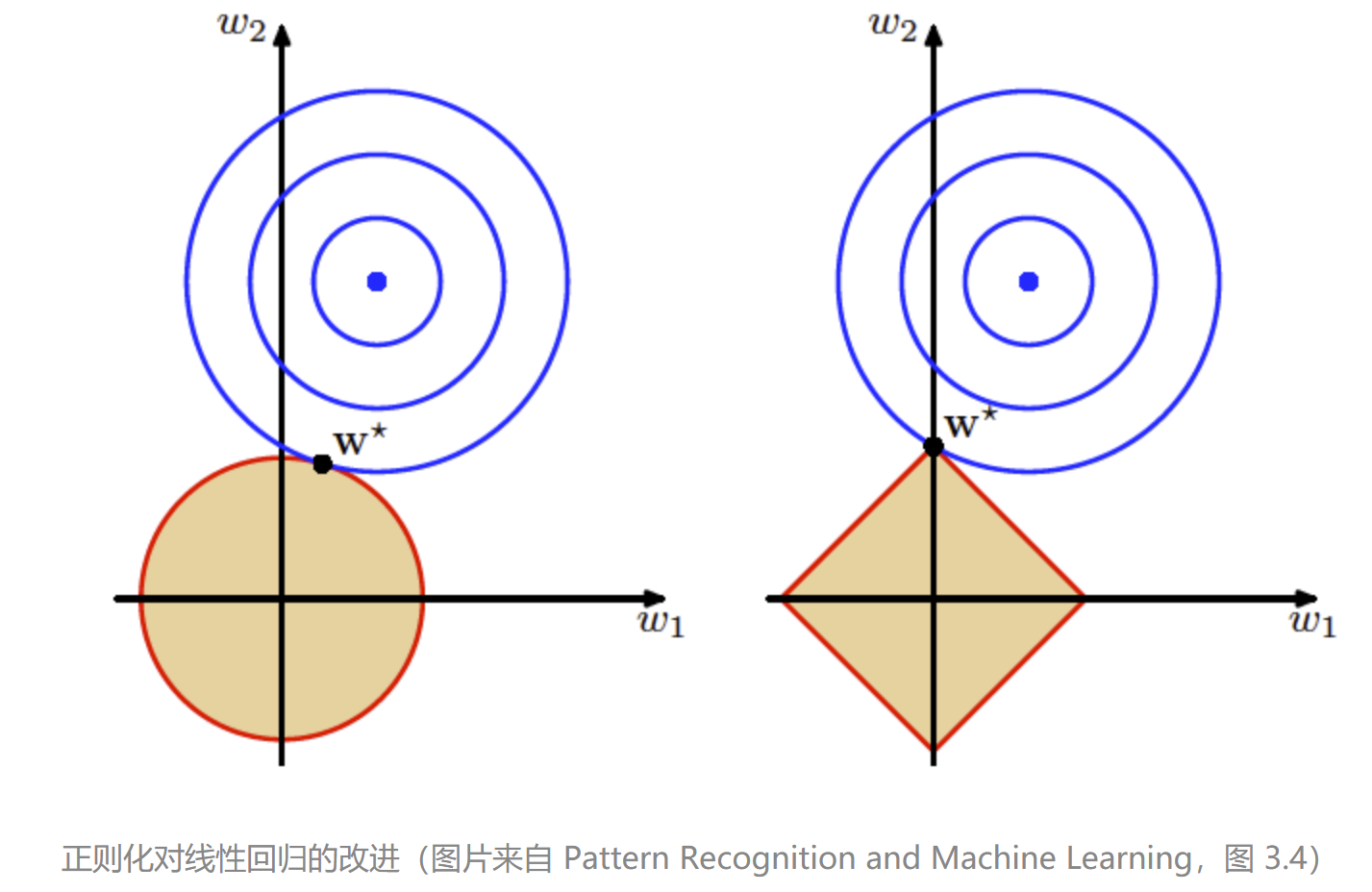
红色边界表示的则是正则化项对参数可能取值的约束,这里假定了未知参数的数目是两个。岭回归中要求两个参数的平方和小于某个固定的取值,即 $w_1 ^2 + w_2 ^ 2 < t$,因此解空间就是浅色区域代表的圆形;而 LASSO 要求两个参数的绝对值之和小于某个固定的取值,即 $|w_1| + |w_2| < t$,因此解空间就是浅色区域代表的方形。
圆形的岭回归边界是平滑的曲线,误差等值线可能在任何位置和边界相切。相形之下,方形的 LASSO 边界是有棱有角的直线,因此切点最可能出现在方形的顶点上,这就意味着某个参数的取值被衰减为 0。这张图形象地说明了岭回归和 LASSO 的区别。岭回归的作用是衰减不同属性的权重,让所有属性一起向圆心收拢;LASSO 则直接将某些属性的权重降低为 0,完成的是属性过滤的任务。
在编程中,很多第三方的 Python 库都可以直接实现不同的正则化处理。在 Scikit-learn 库中,线性模型模块 linear_model 中的 Lasso 类和 Ridge 类就可以实现 $l_1$ 正则化和 $l_2$ 正则化。使用这两个类对前面文章中拟合出来的多元线性回归模型进行正则化处理,将两种算法中的正则化项参数均设置为 $\lambda = 0.05$,就可以得到修正后的结果,代码如下:
1 | import pandas as pd |
所得系数结果如下:
1 | The coefficients of linear regression is: |
线性系数的变化直观地体现出两种正则化的不同效果。在未经正则化的多元线性回归中,第一个系数比较反直觉,为负,因为它意味着门将的表现对球队积分起到的是负作用,这种结论明显不合常理。
这个问题在两种正则化操作中都得以解决。
LASSO 将 4 个特征中 2 个的系数缩减为 0,这意味着一半的特征被淘汰掉了,其中就包括倒霉的守门员。在 LASSO 看来,对比赛做出贡献的只有中场和前锋球员,而中场的作用又远远不及前锋——这样的结果是否是对英超注重进攻的直观印象的佐证呢?
和 LASSO 相比,岭回归保留了所有的特征,并给门将的表现赋予了接近于 0 的权重系数,以削弱它对结果的影响,其它的权重系数也和原始多元回归的结果更加接近。但 LASSO 和岭回归的均方误差都高于普通线性回归的均方误差,LASSO 的性能还要劣于岭回归的性能,这是抑制过拟合和降低误差必然的结果。
比较岭回归和LASSO回归的使用场景:
当参数的数目远远大于样本的数目的高维统计问题,并且参数的选择比较简单粗暴,其中有不少参数存在相关性时,比较建议用LASSO回归来降低参数数目。这样处理后才能做矩阵求逆运算。
LASSO回归会让很多参数的系数变成零,只保留一部分参数,一般是保留系数最大的,系数小的因子很可能是噪音。参数取值的幅度有可能不一样,比如有的参数是-1到1,有的是-10到10,那么系数也会受影响。因此,在使用LASSO之前,需要对参数的取值幅度进行调整,这样计算出来的系数才具有可比性。
当样本数远大于参数的数目时,岭回归计算更快。如果参数数量少而精,数值都调整好,偏度、峰度、正态化、去极值等等,而且普遍适用多种场景,参数可解释,这时比较适合用岭回归。
岭回归不会删除参数,会对参数的取值幅度进行压缩。特征值小的特征向量会被压缩得最厉害,因此,它也要求参数取值幅度最好差不多,这样系数差不多,压缩起来才更有意义。